本文合作者:laybxc
赛事信息
A. Split it!
题目
题目描述
给出一个长度为 n n n s s s k k k
s = a 1 + a 2 + ⋯ + a k + a k + 1 + R ( a k ) + R ( a k − 1 ) + ⋯ + R ( a 1 ) s=a_1+a_2+\dots+a_k+a_{k+1}+R(a_k)+R(a_{k-1})+\dots+R(a_1) s = a 1 + a 2 + ⋯ + a k + a k + 1 + R ( a k ) + R ( a k − 1 ) + ⋯ + R ( a 1 )
其中, R ( x ) R(x) R ( x ) x x x
输入格式
第一行是一个整数 t ( 1 ≤ t ≤ 100 ) t(1≤t≤100) t ( 1 ≤ t ≤ 1 0 0 )
每组数据第一行有两个整数 n , k ( 1 ≤ n ≤ 100 , 0 ≤ k ≤ ⌊ n 2 ⌋ ) n,k(1≤n≤100,0≤k≤⌊\frac n 2⌋) n , k ( 1 ≤ n ≤ 1 0 0 , 0 ≤ k ≤ ⌊ 2 n ⌋ ) k k k
每组数据第二行是一个长度为 n n n s s s
输出格式
如果可以合法划分,则输出YES,否则输出NO。
输出大写或小写都可以。
输入输出样例
输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 7 5 1 qwqwq 2 1 ab 3 1 ioi 4 2 icpc 22 0 dokidokiliteratureclub 19 8 imteamshanghaialice 6 3 aaaaaa
输出
说明/提示
对于第一组数据,一种可能的划分结果为: a 1 = q w , a 2 = q a_1 = qw, a_2 = q a 1 = q w , a 2 = q
对于第二组数据,一种可能的划分结果为: a 1 = i , a 2 = o a_1 = i, a_2 = o a 1 = i , a 2 = o
对于第三组数据,一种可能的划分结果为: a 1 = d o k i d o k i l i t e r a t u r e c l u b a_1 = dokidokiliteratureclub a 1 = d o k i d o k i l i t e r a t u r e c l u b
解决方案
思路
注意到 a 1 + a 2 + ⋯ + a k a_1+a_2+\dots+a_k a 1 + a 2 + ⋯ + a k R ( a k ) + R ( a k − 1 ) + ⋯ + R ( a 1 ) R(a_k)+R(a_{k-1})+\dots+R(a_1) R ( a k ) + R ( a k − 1 ) + ⋯ + R ( a 1 )
因此,对于一个字符串 s s s k k k
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <cstdio> using namespace std ;const int maxn = 1050 ;int t, n, k;char s[maxn];bool check () int i = 1 , j = n; while (s[i] == s[j] && i < j) { i++; j--; } if (i <= j) { if (i - 1 >= k) return true ; else return false ; } if (i > j) { if (i - 2 >= k) return true ; else return false ; } } int main () scanf ("%d" , &t); while (t) { scanf ("%d %d" , &n, &k); scanf ("%s" , s + 1 ); if (check()) printf ("YES\n" ); else printf ("NO\n" ); t--; } return 0 ; }
B. Max and Mex
题目
题目描述
定义 m a x ( S ) max(S) m a x ( S ) S S S m e x ( S ) mex(S) m e x ( S ) S S S
给定一个整数集 S S S ⌈ m a x ( S ) + m e x ( S ) 2 ⌉ ⌈\frac {max(S) + mex(S)} {2} ⌉ ⌈ 2 m a x ( S ) + m e x ( S ) ⌉ S S S k k k S S S
输入格式
第一行一个整数 t t t
每组数据第一行包含两个整数 n , k n,k n , k S S S
每组数据第二行包含这 n n n a 1 , a 2 , … , a n a_1, a_2, \dots, a_n a 1 , a 2 , … , a n S S S
输出格式
输出 k k k S S S
输入输出样例
输入
1 2 3 4 5 6 7 8 9 10 11 5 4 1 0 1 3 4 3 1 0 1 4 3 0 0 1 4 3 2 0 1 2 3 2 1 2 3
输出
说明/提示
对于第一组数据,插入 3 3 3 S S S { 0 , 1 , 3 , 3 , 4 } \{0,1,3,3,4\} { 0 , 1 , 3 , 3 , 4 } 4 4 4
对于第二组数据,插入 3 3 3 S S S { 0 , 1 , 3 , 4 } \{0,1,3,4\} { 0 , 1 , 3 , 4 } 4 4 4
解决方案
思路
设 S S S c n t cnt c n t
先计算第一次操作获得的 ⌈ m a x ( S ) + m e x ( S ) 2 ⌉ ⌈\frac {max(S) + mex(S)} {2} ⌉ ⌈ 2 m a x ( S ) + m e x ( S ) ⌉ m i d mid m i d
m i d < m a x mid < max m i d < m a x m i d mid m i d S S S
则不论操作多少次, m i d mid m i d c n t cnt c n t
m i d < m a x mid < max m i d < m a x m i d mid m i d S S S 不 存在:
则不论操作多少次, m i d mid m i d S S S c n t + 1 cnt+1 c n t + 1
m i d ≥ m a x mid ≥ max m i d ≥ m a x
易见,每次操作中, m i d = m e x = m a x + 1 mid=mex = max + 1 m i d = m e x = m a x + 1 S S S c n t + k cnt+k c n t + k
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <iostream> #include <cstdio> #include <algorithm> using namespace std ;const int maxn = 100500 ;int t, n, k;int MAX, MEX, MID, cnt;int a[maxn];int main () scanf ("%d" , &t); a[0 ] = -1 ; while (t) { scanf ("%d %d" , &n, &k); for (int i=1 ; i<=n; i++) { scanf ("%d" , &a[i]); } sort(a+1 , a+1 +n); cnt = 0 ; for (int i=1 ; i<=n; i++) { if (a[i] != a[i-1 ]) cnt++; } if (k == 0 ) { t--; printf ("%d\n" , cnt); continue ; } MAX = a[n]; bool flag = true ; for (int i=0 ; i<=n-1 ; i++) { if (a[i+1 ] - a[i] >= 2 ) { MEX = a[i] + 1 ; flag = false ; break ; } } if (flag) MEX = a[n] + 1 ; if (MEX < MAX) { if ((MEX + MAX) % 2 == 1 ) MID = (MEX + MAX + 1 ) / 2 ; else MID = (MEX + MAX) / 2 ; flag = false ; for (int i=1 ; i<=n; i++) { if (a[i] == MID) { flag = true ; break ; } } if (flag) printf ("%d\n" , cnt); else printf ("%d\n" , cnt + 1 ); } else { printf ("%d\n" , cnt + k); } t--; } return 0 ; }
C. Diamond Miner
题目
题目描述
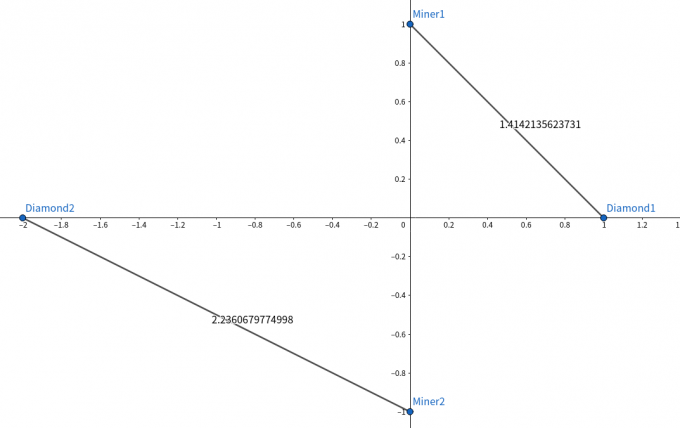
x x x n n n y y y n n n x x x y y y
输入格式
第一行一个整数 t ( 1 ≤ t ≤ 10 ) t(1≤t≤10) t ( 1 ≤ t ≤ 1 0 )
每组数据第一行包含一个整数 n ( 1 ≤ n ≤ 1 0 5 ) n(1≤n≤10^5) n ( 1 ≤ n ≤ 1 0 5 ) x x x y y y
接下来 2 n 2n 2 n x ( − 1 0 8 ≤ x ≤ 1 0 8 ) , y ( − 1 0 8 ≤ y ≤ 1 0 8 ) x(-10^8≤x≤10^8), y(-10^8≤y≤10^8) x ( − 1 0 8 ≤ x ≤ 1 0 8 ) , y ( − 1 0 8 ≤ y ≤ 1 0 8 ) x x x y y y 2 n 2n 2 n
输出格式
对于每组数据,输出一个实数表示答案。
一般地,设你的答案为 a a a b b b
∣ a − b ∣ m a x ( 1 , ∣ b ∣ ) ≤ 1 0 − 9 \frac {|a-b|} {max(1, |b|)} ≤ 10^{-9}
m a x ( 1 , ∣ b ∣ ) ∣ a − b ∣ ≤ 1 0 − 9
输入输出样例
输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 3 2 0 1 1 0 0 -1 -2 0 4 1 0 3 0 -5 0 6 0 0 3 0 1 0 2 0 4 5 3 0 0 4 0 -3 4 0 2 0 1 0 -3 0 0 -10 0 -2 0 -10
输出
1 2 3 3.650281539872885 18.061819283610362 32.052255376143336
说明/提示
对于第一组数据,方案如下,结果为 2 + 5 \sqrt{2} + \sqrt{5} 2 + 5
解决方案
思路
贪心做法,每次连接 x x x y y y O ( n log n ) O(n\log_{}{n}) O ( n log n )
证明
MAGIC
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <iostream> #include <cstdio> #include <queue> #include <cmath> using namespace std ;const int maxn = 100500 ;class Point //定义点类{ public : long long x, y, dis; Point(long long x_, long long y_) { x = x_; y = y_; dis = sqrt (x * x + y * y); } bool operator <(const Point &b) const { return dis > b.dis; } }; int t, n;double ans;priority_queue <Point> X, Y; double P_dis (Point a, Point b) return sqrt ((a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y)); } int main () scanf ("%d" , &t); while (t--) { ans = 0 ; while (!X.empty()) X.pop(); while (!Y.empty()) Y.pop(); scanf ("%d" , &n); for (int i = 1 ; i <= n * 2 ; i++) { long long x, y; scanf ("%lld %lld" , &x, &y); Point tmp (x, y) ; if (y == 0 ) { X.push(tmp); } if (x == 0 ) { Y.push(tmp); } } while (X.size() > n) { X.pop(); } while (Y.size() > n) { Y.pop(); } while (!X.empty()) { ans += P_dis(X.top(), Y.top()); X.pop(); Y.pop(); } printf ("%.15lf\n" , ans); } return 0 ; }
D. Let’s Go Hiking
题目
题目描述
有 n n n 1 ∼ n 1 \sim n 1 ∼ n
Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l
Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l
Q i n g s h a n Qingshan Q i n g s h a n x x x D a n i e l Daniel D a n i e l y y y
轮到某人时如果他不能移动,则对方获胜。
若两人都采取最优策略,问 Q i n g s h a n Qingshan Q i n g s h a n
输入格式
第一行一个整数,表示参数 n ( 2 ≤ n ≤ 1 0 5 ) n(2≤n≤10^5) n ( 2 ≤ n ≤ 1 0 5 )
第二行 n n n p 1 , p 2 , … , p n p_1, p_2, \dots, p_n p 1 , p 2 , … , p n 1 ∼ n 1 \sim n 1 ∼ n
输出格式
输出能使 Q i n g s h a n Qingshan Q i n g s h a n
输入输出样例
输入 #1
输出 #1
输入 #2
输出 #2
说明/提示
对于第一组数据, Q i n g s h a n Qingshan Q i n g s h a n x = 3 x=3 x = 3 1。
对于第二组数据,如果 Q i n g s h a n Qingshan Q i n g s h a n x = 4 x=4 x = 4 D a n i e l Daniel D a n i e l y = 1 y=1 y = 1 Q i n g s h a n Qingshan Q i n g s h a n x = 3 x=3 x = 3 D a n i e l Daniel D a n i e l y = 2 y=2 y = 2 Q i n g s h a n Qingshan Q i n g s h a n x = 2 x=2 x = 2 D a n i e l Daniel D a n i e l Q i n g s h a n Qingshan Q i n g s h a n 0。
解决方案
思路
Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l Q i n g s h a n Qingshan Q i n g s h a n Q i n g s h a n Qingshan Q i n g s h a n Q i n g s h a n Qingshan Q i n g s h a n
Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l Q i n g s h a n Qingshan Q i n g s h a n Q i n g s h a n Qingshan Q i n g s h a n
当 Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l Q i n g s h a n Qingshan Q i n g s h a n Q i n g s h a n Qingshan Q i n g s h a n Q i n g s h a n Qingshan Q i n g s h a n Q i n g s h a n Qingshan Q i n g s h a n D a n i e l Daniel D a n i e l
至此,程序的编写就不难了:
先为 Q i n g s h a n Qingshan Q i n g s h a n
然后为 D a n i e l Daniel D a n i e l
此时判断 D a n i e l Daniel D a n i e l 0,表明 Q i n g s h a n Qingshan Q i n g s h a n 1。
没错,你会发现只有0或1两种答案,如果这是OI赛制的题,随机输出就能得 50 50 5 0
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 #include <iostream> #include <cstdio> using namespace std ;const int maxn = 100500 ;int n, ls, qingshan_spawn, direction, daniel_spawn;int a[maxn], left_path_length[maxn], right_path_length[maxn];int dfs (int loc, int pace) int *p = pace == -1 ? &left_path_length[loc] : &right_path_length[loc]; if (loc + pace == 0 || loc + pace == n + 1 ) return *p = 0 ; if (a[loc] < a[loc + pace]) return *p = 0 ; return *p = dfs(loc + pace, pace) + 1 ; } int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i++) { scanf ("%d" , &a[i]); } for (int i = 1 ; i <= n; i++) { if (i == 1 && a[i] > a[i + 1 ]) dfs(i, 1 ); else if (i == n && a[i - 1 ] < a[i]) dfs(i, -1 ); else if (a[i] > a[i - 1 ] && a[i] > a[i + 1 ]) { dfs(i, -1 ); dfs(i, 1 ); } } bool flag = true ; for (int i = 1 ; i <= n; i++) { if (left_path_length[i] == 0 || right_path_length[i] == 0 ) continue ; if (left_path_length[i] > ls) { ls = left_path_length[i]; qingshan_spawn = i; direction = -1 ; } if (right_path_length[i] > ls) { ls = right_path_length[i]; qingshan_spawn = i; direction = 1 ; } flag = false ; } if (flag) { printf ("0" ); return 0 ; } for (int i = 1 ; i <= n; i++) { if (i == qingshan_spawn) continue ; if (left_path_length[i] == left_path_length[qingshan_spawn] || right_path_length[i] == left_path_length[qingshan_spawn]) { printf ("0" ); return 0 ; } if (left_path_length[i] == right_path_length[qingshan_spawn] || right_path_length[i] == right_path_length[qingshan_spawn]) { printf ("0" ); return 0 ; } } if (direction == -1 ) { daniel_spawn = left_path_length[qingshan_spawn] % 2 == 0 ? qingshan_spawn - left_path_length[qingshan_spawn] + 1 : qingshan_spawn - left_path_length[qingshan_spawn]; direction = 1 ; } else { daniel_spawn = right_path_length[qingshan_spawn] % 2 == 0 ? qingshan_spawn + right_path_length[qingshan_spawn] - 1 : qingshan_spawn + right_path_length[qingshan_spawn]; direction = -1 ; } if (direction == -1 ) { printf ("%d" , left_path_length[qingshan_spawn] > daniel_spawn - qingshan_spawn); } else { printf ("%d" , right_path_length[qingshan_spawn] > qingshan_spawn - daniel_spawn); } return 0 ; }
请参阅