# Load the raw CIFAR-10 data. cifar10_dir = r'D:\Users\VonBrank\Documents\GitHub\code-learning\algorithm\deep-learning\computer-visualization\cs231n\datasets\cifar-10-batches-py'
import random import numpy as np from cs231n.data_utils import load_CIFAR10 import matplotlib.pyplot as plt
# This is a bit of magic to make matplotlib figures appear inline in the notebook # rather than in a new window. %matplotlib inline plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray'
# Some more magic so that the notebook will reload external python modules; # see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython %load_ext autoreload %autoreload 2
加载数据
In[2]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Load the raw CIFAR-10 data. cifar10_dir = r'D:\Users\VonBrank\Documents\GitHub\code-learning\algorithm\deep-learning\computer-visualization\cs231n\datasets\cifar-10-batches-py'
# Cleaning up variables to prevent loading data multiple times (which may cause memory issue) try: del X_train, y_train del X_test, y_test print('Clear previously loaded data.') except: pass
# As a sanity check, we print out the size of the training and test data. print('Training data shape: ', X_train.shape) print('Training labels shape: ', y_train.shape) print('Test data shape: ', X_test.shape) print('Test labels shape: ', y_test.shape)
Out[2]
1 2 3 4
Training data shape: (50000, 32, 32, 3) Training labels shape: (50000,) Test data shape: (10000, 32, 32, 3) Test labels shape: (10000,)
预处理数据
随机选取一些图像并输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# Visualize some examples from the dataset. # We show a few examples of training images from each class. classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] num_classes = len(classes) samples_per_class = 7 for y, cls inenumerate(classes): idxs = np.flatnonzero(y_train == y) idxs = np.random.choice(idxs, samples_per_class, replace=False) for i, idx inenumerate(idxs): plt_idx = i * num_classes + y + 1 plt.subplot(samples_per_class, num_classes, plt_idx) plt.imshow(X_train[idx].astype('uint8')) plt.axis('off') if i == 0: plt.title(cls) plt.show()
选取CIFAR-10的一个子集进行训练与测试
In[3]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Subsample the data for more efficient code execution in this exercise num_training = 5000 mask = list(range(num_training)) X_train = X_train[mask] y_train = y_train[mask]
# Reshape the image data into rows X_train = np.reshape(X_train, (X_train.shape[0], -1)) X_test = np.reshape(X_test, (X_test.shape[0], -1)) print(X_train.shape, X_test.shape)
Out[3]
1
(5000, 3072) (500, 3072)
调用KNN算法
1 2 3 4 5 6 7
from cs231n.classifiers import KNearestNeighbor
# Create a kNN classifier instance. # Remember that training a kNN classifier is a noop: # the Classifier simply remembers the data and does no further processing classifier = KNearestNeighbor() classifier.train(X_train, y_train)
defcompute_distances_two_loops(self, X): """ Compute the distance between each test point in X and each training point in self.X_train using a nested loop over both the training data and the test data. Inputs: - X: A numpy array of shape (num_test, D) containing test data. Returns: - dists: A numpy array of shape (num_test, num_train) where dists[i, j] is the Euclidean distance between the ith test point and the jth training point. """ num_test = X.shape[0] num_train = self.X_train.shape[0] dists = np.zeros((num_test, num_train)) for i inrange(num_test): for j inrange(num_train): ##################################################################### # TODO: # # Compute the l2 distance between the ith test point and the jth # # training point, and store the result in dists[i, j]. You should # # not use a loop over dimension, nor use np.linalg.norm(). # ##################################################################### # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** dists[i][j] = np.sqrt(np.sum((X[i, :] - self.X_train[j, :]) ** 2)) pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** return dists
验证计算是否正确:
In[4]
1 2 3 4 5 6
# Open cs231n/classifiers/k_nearest_neighbor.py and implement # compute_distances_two_loops.
# Test your implementation: dists = classifier.compute_distances_two_loops(X_test) print(dists.shape)
Out[4]
1
(500, 5000)
可视化结果:
In[5]
1 2 3 4
# We can visualize the distance matrix: each row is a single test example and # its distances to training examples plt.imshow(dists, interpolation='none') plt.show()
Out[6]
其中,白线意味着对应位置的训练集和测试集相似度非常低。
测试一下:
In[6]
1 2 3 4 5 6 7 8
# Now implement the function predict_labels and run the code below: # We use k = 1 (which is Nearest Neighbor). y_test_pred = classifier.predict_labels(dists, k=1)
defcompute_distances_one_loop(self, X): """ Compute the distance between each test point in X and each training point in self.X_train using a single loop over the test data. Input / Output: Same as compute_distances_two_loops """ num_test = X.shape[0] num_train = self.X_train.shape[0] dists = np.zeros((num_test, num_train)) for i inrange(num_test): ####################################################################### # TODO: # # Compute the l2 distance between the ith test point and all training # # points, and store the result in dists[i, :]. # # Do not use np.linalg.norm(). # ####################################################################### # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** dists[i, :] = np.sqrt(np.sum(((X[i] - self.X_train) ** 2), axis=1)) # pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** return dists
测试一下:
In[8]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# Now lets speed up distance matrix computation by using partial vectorization # with one loop. Implement the function compute_distances_one_loop and run the # code below: dists_one = classifier.compute_distances_one_loop(X_test)
# To ensure that our vectorized implementation is correct, we make sure that it # agrees with the naive implementation. There are many ways to decide whether # two matrices are similar; one of the simplest is the Frobenius norm. In case # you haven't seen it before, the Frobenius norm of two matrices is the square # root of the squared sum of differences of all elements; in other words, reshape # the matrices into vectors and compute the Euclidean distance between them. difference = np.linalg.norm(dists - dists_one, ord='fro') print('One loop difference was: %f' % (difference, )) if difference < 0.001: print('Good! The distance matrices are the same') else: print('Uh-oh! The distance matrices are different')
Out[8]
1 2
One loop difference was: 0.000000 Good! The distance matrices are the same
defcompute_distances_no_loops(self, X): """ Compute the distance between each test point in X and each training point in self.X_train using no explicit loops. Input / Output: Same as compute_distances_two_loops """ num_test = X.shape[0] num_train = self.X_train.shape[0] dists = np.zeros((num_test, num_train)) ######################################################################### # TODO: # # Compute the l2 distance between all test points and all training # # points without using any explicit loops, and store the result in # # dists. # # # # You should implement this function using only basic array operations; # # in particular you should not use functions from scipy, # # nor use np.linalg.norm(). # # # # HINT: Try to formulate the l2 distance using matrix multiplication # # and two broadcast sums. # ######################################################################### # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** return dists
测试一下:
In[9]
1 2 3 4 5 6 7 8 9 10 11
# Now implement the fully vectorized version inside compute_distances_no_loops # and run the code dists_two = classifier.compute_distances_no_loops(X_test)
# check that the distance matrix agrees with the one we computed before: difference = np.linalg.norm(dists - dists_two, ord='fro') print('No loop difference was: %f' % (difference, )) if difference < 0.001: print('Good! The distance matrices are the same') else: print('Uh-oh! The distance matrices are different')
Out[9]
1 2
No loop difference was: 0.000000 Good! The distance matrices are the same
# Let's compare how fast the implementations are deftime_function(f, *args): """ Call a function f with args and return the time (in seconds) that it took to execute. """ import time tic = time.time() f(*args) toc = time.time() return toc - tic
two_loop_time = time_function(classifier.compute_distances_two_loops, X_test) print('Two loop version took %f seconds' % two_loop_time)
one_loop_time = time_function(classifier.compute_distances_one_loop, X_test) print('One loop version took %f seconds' % one_loop_time)
no_loop_time = time_function(classifier.compute_distances_no_loops, X_test) print('No loop version took %f seconds' % no_loop_time)
# You should see significantly faster performance with the fully vectorized implementation!
# NOTE: depending on what machine you're using, # you might not see a speedup when you go from two loops to one loop, # and might even see a slow-down.
Out[10]
1 2 3
Two loop version took 24.983689 seconds One loop version took 38.931001 seconds No loop version took 0.206878 seconds
X_train_folds = [] y_train_folds = [] ################################################################################ # TODO: # # Split up the training data into folds. After splitting, X_train_folds and # # y_train_folds should each be lists of length num_folds, where # # y_train_folds[i] is the label vector for the points in X_train_folds[i]. # # Hint: Look up the numpy array_split function. # ################################################################################ # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** X_train_folds = np.split(X_train, num_folds) y_train_folds = np.split(y_train, num_folds) # print(X_train_folds[1].shape) # print(y_train_folds[1].shape) pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# A dictionary holding the accuracies for different values of k that we find # when running cross-validation. After running cross-validation, # k_to_accuracies[k] should be a list of length num_folds giving the different # accuracy values that we found when using that value of k. k_to_accuracies = {}
################################################################################ # TODO: # # Perform k-fold cross validation to find the best value of k. For each # # possible value of k, run the k-nearest-neighbor algorithm num_folds times, # # where in each case you use all but one of the folds as training data and the # # last fold as a validation set. Store the accuracies for all fold and all # # values of k in the k_to_accuracies dictionary. # ################################################################################ # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** for k in k_choices: k_to_accuracies[k] = np.zeros(num_folds) acc = [] for i inrange(0, num_folds): X_tr = X_train_folds[: i] + X_train_folds[i+1 :] y_tr = y_train_folds[: i] + y_train_folds[i+1 :] X_tr = np.concatenate(X_tr, axis=0) y_tr = np.concatenate(y_tr, axis=0) classifier = KNearestNeighbor() classifier.train(X_tr, y_tr) X_cv = X_train_folds[i] y_cv = y_train_folds[i] y_cv_pred = classifier.predict(X_cv, k=k, num_loops=0) num_correst = np.mean(y_cv_pred == y_cv) acc.append(num_correst) k_to_accuracies[k] = acc # pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Print out the computed accuracies for k insorted(k_to_accuracies): for accuracy in k_to_accuracies[k]: print('k = %d, accuracy = %f' % (k, accuracy))
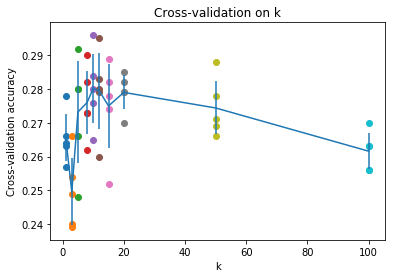
k = 1, accuracy = 0.263000 k = 1, accuracy = 0.257000 k = 1, accuracy = 0.264000 k = 1, accuracy = 0.278000 k = 1, accuracy = 0.266000 k = 3, accuracy = 0.239000 k = 3, accuracy = 0.249000 k = 3, accuracy = 0.240000 k = 3, accuracy = 0.266000 k = 3, accuracy = 0.254000 k = 5, accuracy = 0.248000 k = 5, accuracy = 0.266000 k = 5, accuracy = 0.280000 k = 5, accuracy = 0.292000 k = 5, accuracy = 0.280000 k = 8, accuracy = 0.262000 k = 8, accuracy = 0.282000 k = 8, accuracy = 0.273000 k = 8, accuracy = 0.290000 k = 8, accuracy = 0.273000 k = 10, accuracy = 0.265000 k = 10, accuracy = 0.296000 k = 10, accuracy = 0.276000 k = 10, accuracy = 0.284000 k = 10, accuracy = 0.280000 k = 12, accuracy = 0.260000 k = 12, accuracy = 0.295000 k = 12, accuracy = 0.279000 k = 12, accuracy = 0.283000 k = 12, accuracy = 0.280000 k = 15, accuracy = 0.252000 k = 15, accuracy = 0.289000 k = 15, accuracy = 0.278000 k = 15, accuracy = 0.282000 k = 15, accuracy = 0.274000 k = 20, accuracy = 0.270000 k = 20, accuracy = 0.279000 k = 20, accuracy = 0.279000 k = 20, accuracy = 0.282000 k = 20, accuracy = 0.285000 k = 50, accuracy = 0.271000 k = 50, accuracy = 0.288000 k = 50, accuracy = 0.278000 k = 50, accuracy = 0.269000 k = 50, accuracy = 0.266000 k = 100, accuracy = 0.256000 k = 100, accuracy = 0.270000 k = 100, accuracy = 0.263000 k = 100, accuracy = 0.256000 k = 100, accuracy = 0.263000
可视化结果:
In[12]
1 2 3 4 5 6 7 8 9 10 11 12 13
# plot the raw observations for k in k_choices: accuracies = k_to_accuracies[k] plt.scatter([k] * len(accuracies), accuracies)
# plot the trend line with error bars that correspond to standard deviation accuracies_mean = np.array([np.mean(v) for k,v insorted(k_to_accuracies.items())]) accuracies_std = np.array([np.std(v) for k,v insorted(k_to_accuracies.items())]) plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std) plt.title('Cross-validation on k') plt.xlabel('k') plt.ylabel('Cross-validation accuracy') plt.show()
Out[12]
可以发现在此数据集下, k=10 时效果最好。
现在可以跑一跑测试集了:
In[13]
1 2 3 4 5 6 7 8 9 10 11 12 13
# Based on the cross-validation results above, choose the best value for k, # retrain the classifier using all the training data, and test it on the test # data. You should be able to get above 28% accuracy on the test data. best_k = 10